责任链模式的实践与思考
一、应用场景
我的理解是:某些复杂的逻辑,可以抽象成对于特定的对象,经过传递到各个环节的依次处理,形成一个链式的流程,每个环节都有自己独立的职责,
便可以尝试使用责任链模式,用于逻辑拆分和解耦,也可以让冗长的代码更加优雅。
这样的设计可以更好地应用单一职责原则、迪米特法则。
在资源迁移这种具有复杂的逻辑,但也可以抽象成环环相扣的链式处理场景上,首次尝试使用了责任链模式,期间遇到不少问题和坑点,也有在使用优雅/内存占用优化/调试和看堆栈方便之间的权衡纠结,故作此文,以记录之。
二、简单实现方式
1.实现
传统的、简单的实现方式:每个环节都接收同样的参数(一个对象,或一个基本类型的值),按顺序各自处理,直到没有下一个可执行的环节。
简单示例:
接口:
public interface Chain {
/**
* 获取责任链上下一个环节
*/
@Nullable
Chain getNext();
void setNext(Chain chain);
void handle(Object param);
}抽象实现:
public abstract class AbstractChain implements Chain {
private Chain next;
@Override
public final Chain getNext() {
return next;
}
@Override
public final void setNext(Chain chain) {
next = chain;
}
}简单的环节实现:
public class SimpleChain extends AbstractChain{
@Override
public void handle(Object param) {
// do business...
if (null != getNext()) {
getNext().handle(param);
}
}
}这样,一个简单的责任链就实现好了。
2.缺点
但是,这样的实现有很多不便之处,比如:
①构造责任链的时候,需要new一个第一层的对象,然后调用其setNext()方法,而这个方法又是void返回值的,所以在set之前,需要先把第二层的对象构造出来,并调用其setNext()先设置第三层的,以此类推,
就非常的麻烦,写起来不顺手且不能直观看出谁的下一环节是谁;
②另一方面,每个环节都需要getNext()或者next改为protected,但也需要在各自的执行逻辑中判断下一环节是否存在,对于编写各个环节来说,不应该关心这个问题,且造成了很多冗余逻辑在里面;
③一些环节内需要使用局部变量,会维持虚拟机栈到堆上的一些对象的强引用,在handle()方法中最后进入下一环节,则将会导致当前环节已经使用过的局部对象的引用不能被立即消除,如果这个链式的调用很长很长,则将有很多实际已经不需要的对象无法被回收,此时的内存占用表现将比传统的面向过程处理,抽成一个个方法的实现方式,还要差;
④参数需要指定固定的类型,扩展性不好
⑤不支持返回值,某些需要链式处理结果的场景将无法发挥价值
3.缺点的优化思路
与上面一一对应。
①构造的方式修改
可以将构造方法改为简单的builder模式,不过不同于传统的builder返回对象自身,这里需要返回参数自身:
@Override
public final Chain setNext(Chain next) {
this.next = next;
return next;
}如此一来,可以使用链式构造,更加优雅,如:
new SimpleChain()
.setNext(new SimpleChain1())
.setNext(new SimpleChain2())
.setNext(new SimpleChain3());但是也有一些问题,踩到了坑,因为最终返回值一定是最后一个环节,所以要使用这个责任链,需要拿到第一个环节对象的引用,则需要注册前,先存一个第一个对象的引用,来后续调用执行,还是不够优雅:
SimpleChain simpleChain = new SimpleChain();
simpleChain
.setNext(new SimpleChain1())
.setNext(new SimpleChain2())
.setNext(new SimpleChain3());
simpleChain.handle(new Object());所以,想了想,还得靠一个构造器来完成:
public class ChainBuilder {
private Chain head;
private Chain tail;
public ChainBuilder next(Chain next) {
if (null == head) {
head = next;
}
if (null != tail) {
tail.setNext(next);
}
tail = next;
return this;
}
public Chain build() {
return head;
}
}这样就可以优雅地构建链了:
Chain chain = new ChainBuilder()
.next(new SimpleChain())
.next(new SimpleChain1())
.next(new SimpleChain2())
.next(new SimpleChain3())
.build();
chain.handle(new Object());②环节自身不需要手动判断/调用下一环节,做到无感知
这个也比较好做到,因为是简单的重复逻辑,提到抽象类即可,先增加接口:
/**
* 从当前环节开始执行
*/
void start(Object param);抽象类实现:
@Override
public final void start(Object param) {
handle(param);
if (null != next) {
next.start(param);
}
}如此一来,所有环节只需要实现handle()方法,在第一环节调用start()方法,即可按顺序执行完成了。
③及时消除局部变量表对堆对象的引用
其实经过了②的优化,已经天然地实现了目的,因为处理逻辑全部在handle()方法中,调用下一环节时,已经销毁当前环节handle()方法的栈帧,自然就没有局部变量的引用了,做到了即用即销,优化内存占用。
④支持不同的参数类型
这个也比较简单,使用泛型即可
⑤支持返回值
返回值的支持,第一点和上面参数类似,需要支持泛型;
其次,返回值的逻辑要明确一下,可以是对同一个对象的连续处理,最终返回这个对象,也可以是链式处理的最后一环返回的对象,按具体的需要来实现,
第一种比较好理解,没有歧义,第二种的话,就需要在handle()方法增加一个返回值,不过中间环节的返回值,实际上都被忽略掉了,只有最后以环节才有意义。
三、最终的实现
经过一系列优化与斟酌,实现了一个通用性较好的责任链架子
接口:
public interface Chain<PARAM, RESULT> {
/**
* 注册下一环节处理器
*
* @param next 下一环节
*/
Chain<PARAM, RESULT> next(Chain<PARAM, RESULT> next);
/**
* 当前环节处理
*/
RESULT handle(PARAM param);
/**
* 从当前环节开始执行
*/
RESULT start(PARAM param);
}抽象实现:
public abstract class BaseChain<PARAM, RESULT> implements Chain<PARAM, RESULT> {
protected Chain<PARAM, RESULT> next;
@Override
public final Chain<PARAM, RESULT> next(Chain<PARAM, RESULT> next) {
this.next = next;
return next;
}
@Override
public final RESULT start(PARAM param) {
RESULT result = handle(param);
if (null != next) {
return next.start(param);
}
return result;
}
}构造器:
public class ChainBuilder<PARAM, RESULT> {
private Chain<PARAM, RESULT> head;
private Chain<PARAM, RESULT> tail;
public ChainBuilder<PARAM, RESULT> next(Chain<PARAM, RESULT> next) {
if (null == head) {
head = next;
}
if (null != tail) {
tail.next(next);
}
tail = next;
return this;
}
public Chain<PARAM, RESULT> build() {
return head;
}
}满足了二中提到的所有缺点的优化。
四、其他的思考
虽然上述的实现满足了基本需要,还是有一点点遗憾,
如在调试时,或者报错时,或看堆栈时,查看上述方式实现的栈,都是在抽象类的start()方法上,只有栈顶的一环节才是在handle(),此时才能看到所处的类的类名,很可能报错堆栈看到的是下面这样:
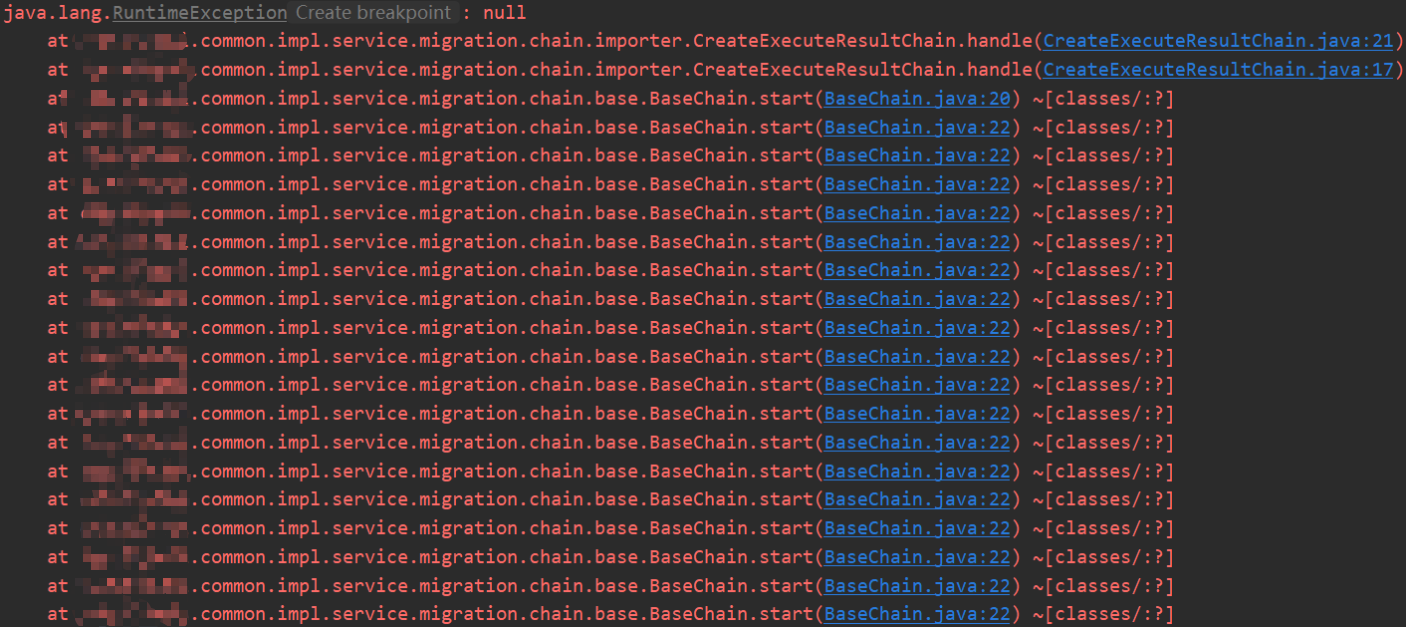
但是,要解决这一问题,就需要有所牺牲:
①比如,可以改回简单实现中的,每个环节的handler()调用下一环节,则堆栈中可清晰查看调用链,但缺点也很明显,增加了冗余代码、环节之间的耦合度、损失了局部变量对象的及时回收,增加了内存占用。
②可以改为各个实现类都重写抽象类中的start()方法,或者直接不需要抽象类的实现了,下放到子类中,则堆栈中可清晰查看调用链,缺点是冗余代码、且误重写的风险不可控。
总之,实现方式需要考虑多方面的因素,有时候各个因素之间会互斥,需要权衡利弊,取其一,或是在一些场景下,不断优化设计,最终达到一个平衡点。

